MapReduce in Hadoop: A Deep Dive into Distributed Information Processing
Associated Articles: MapReduce in Hadoop: A Deep Dive into Distributed Information Processing
Introduction
With nice pleasure, we’ll discover the intriguing subject associated to MapReduce in Hadoop: A Deep Dive into Distributed Information Processing. Let’s weave attention-grabbing info and provide contemporary views to the readers.
Desk of Content material
MapReduce in Hadoop: A Deep Dive into Distributed Information Processing

Hadoop, the open-source framework for distributed storage and processing of enormous datasets, owes a lot of its energy and scalability to its core processing mannequin: MapReduce. This paradigm, initially developed at Google, revolutionized the way in which we deal with large knowledge by enabling parallel processing throughout a cluster of commodity {hardware}. This text delves into the intricacies of MapReduce in Hadoop, exploring its structure, workflow, key parts, benefits, limitations, and its relevance within the trendy large knowledge panorama.
Understanding the MapReduce Paradigm
MapReduce simplifies the advanced activity of processing huge datasets by breaking it down into two elementary levels: the map stage and the scale back stage. This divide-and-conquer method leverages parallelism to dramatically scale back processing time.
-
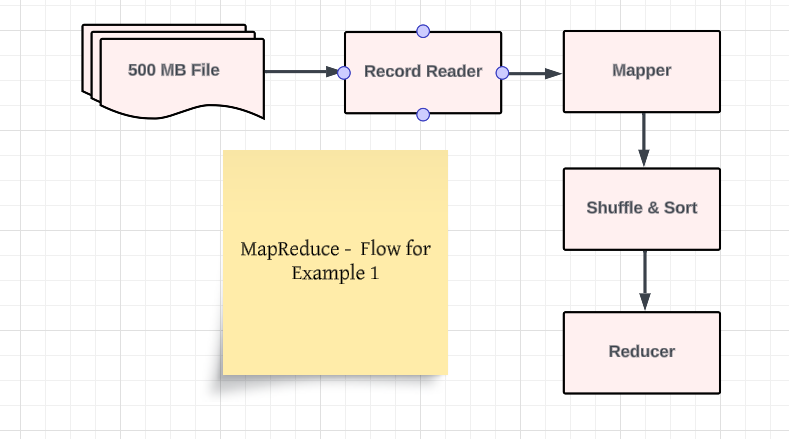
Map Stage: The map stage operates on particular person knowledge information independently. Every enter document is processed by a mapper operate, which transforms the document right into a set of key-value pairs. This transformation can contain filtering, cleansing, aggregating, or some other operation vital to organize the information for the following stage. Crucially, mappers function in parallel, processing totally different knowledge chunks concurrently.
-
Shuffle and Kind Stage: After the map stage, an intermediate step, typically known as the shuffle and kind section, takes place. This significant step includes grouping the key-value pairs produced by the mappers based mostly on their keys. All key-value pairs with the identical key are grouped collectively and sorted, getting ready the information for the scale back stage. This stage handles the community communication and knowledge redistribution throughout the cluster.
-
Scale back Stage: The scale back stage takes the sorted key-value pairs produced by the map stage as enter. For every distinctive key, a reducer operate processes the corresponding values, aggregating or summarizing them to provide a single output worth. This aggregation can contain numerous operations, akin to summing, averaging, counting, or becoming a member of knowledge. Just like the map stage, reducers additionally function in parallel, processing totally different keys concurrently.
Structure of MapReduce in Hadoop
The MapReduce framework in Hadoop consists of a number of key parts that work collectively to orchestrate your complete course of:
-
Shopper: The consumer submits the MapReduce job to the Hadoop cluster. This includes specifying the enter knowledge location, the mapper and reducer capabilities (written in Java, Python, or different supported languages), and the output location.
-
JobTracker (Deprecated in YARN): In older Hadoop variations (earlier than YARN), the JobTracker was a central element liable for scheduling and monitoring the MapReduce job. It manages the duties, tracks their progress, and handles failures. This centralized method turned a bottleneck for very giant clusters.
-
TaskTrackers (Deprecated in YARN): TaskTrackers had been nodes within the cluster that executed the map and scale back duties assigned by the JobTracker.
-
But One other Useful resource Negotiator (YARN): YARN is the present useful resource administration system in Hadoop. It replaces the JobTracker and TaskTracker structure with a extra versatile and scalable method. YARN separates useful resource administration from job scheduling and execution, permitting for higher useful resource utilization and fault tolerance. YARN parts embrace the ResourceManager, NodeManagers, and ApplicationMaster.
-
ResourceManager: The ResourceManager is liable for allocating sources (CPU, reminiscence, and so on.) throughout the cluster.
-
NodeManagers: NodeManagers run on every knowledge node and handle the sources on that node. They obtain requests from the ResourceManager and launch containers to execute duties.
-
ApplicationMaster: The ApplicationMaster is liable for managing the execution of a particular MapReduce job. It negotiates sources from the ResourceManager, launches duties on NodeManagers, and screens their progress.
Workflow of a MapReduce Job
-
Job Submission: The consumer submits the MapReduce job to the Hadoop cluster.
-
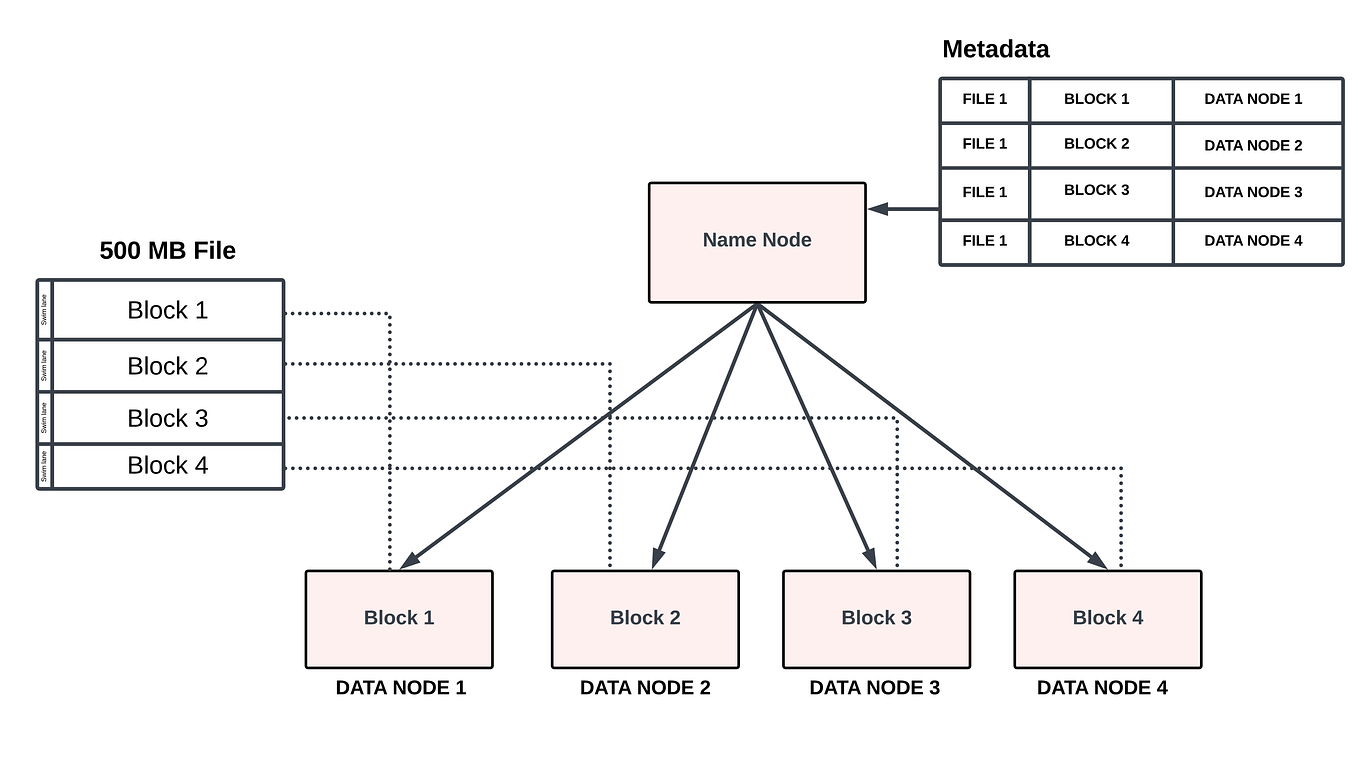
Enter Splitting: The enter knowledge is break up into smaller chunks known as enter splits, that are distributed throughout the information nodes.
-
Map Process Execution: Mappers course of the enter splits independently and produce key-value pairs.
-
Shuffle and Kind: The important thing-value pairs are shuffled and sorted based mostly on their keys.
-
Scale back Process Execution: Reducers course of the sorted key-value pairs for every distinctive key and produce the ultimate output.
-
Output Writing: The output from the reducers is written to the required output location.
-
Job Completion: The consumer receives notification when the job is full.
Instance: Phrase Rely
A traditional instance of MapReduce is phrase counting. The mapper would learn every line of textual content, break up it into phrases, and emit every phrase as a key with a price of 1. The reducer would then obtain all of the (phrase, 1) pairs for every phrase, sum the values, and output the phrase and its rely.
Benefits of MapReduce
-
Scalability: MapReduce can simply deal with huge datasets by distributing the processing throughout a cluster of machines.
-
Fault Tolerance: The framework robotically handles failures by restarting failed duties on different nodes.
-
Parallel Processing: The parallel execution of map and scale back duties considerably reduces processing time.
-
Ease of Programming: The MapReduce programming mannequin is comparatively easy and simple to know, even for builders with out in depth distributed programs expertise.
-
Information Locality: Information is processed regionally on the node the place it’s saved, minimizing knowledge switch overhead.
Limitations of MapReduce
-
Latency: For jobs with low knowledge quantity or these requiring iterative processing, MapReduce might be much less environment friendly than different frameworks.
-
Information Shuffle Overhead: The shuffle and kind section generally is a bottleneck, particularly for jobs with giant intermediate knowledge.
-
Restricted Flexibility: The MapReduce mannequin is greatest fitted to batch processing and is probably not excellent for real-time or interactive purposes.
-
Debugging Complexity: Debugging distributed purposes might be difficult.
MapReduce within the Trendy Massive Information Panorama
Whereas MapReduce was a groundbreaking expertise, its limitations have led to the emergence of extra superior frameworks like Spark, which presents quicker processing speeds and extra flexibility. Nonetheless, MapReduce stays related in a number of eventualities:
-
Batch Processing: For giant-scale batch processing duties, MapReduce stays a strong and dependable resolution.
-
Legacy Techniques: Many organizations nonetheless depend on Hadoop and MapReduce for his or her current large knowledge infrastructure.
-
Particular Use Circumstances: Sure varieties of knowledge processing duties, particularly these involving easy aggregations or transformations, are well-suited for MapReduce.
-
Value-Effectiveness: For organizations with current Hadoop clusters, leveraging MapReduce generally is a cost-effective strategy to course of giant datasets.
Conclusion
MapReduce in Hadoop supplied a elementary shift in how we method large knowledge processing. Its affect remains to be felt immediately, whilst newer applied sciences emerge. Understanding the rules of MapReduce stays essential for anybody working with large knowledge, offering a strong basis for greedy the intricacies of distributed computing and the evolution of huge knowledge frameworks. Whereas its limitations have spurred the event of extra refined options, MapReduce’s contribution to the sector stays plain, paving the way in which for the superior large knowledge applied sciences we use immediately. Its core rules of divide-and-conquer, parallel processing, and fault tolerance proceed to encourage the design of recent distributed processing programs.




Closure
Thus, we hope this text has supplied precious insights into MapReduce in Hadoop: A Deep Dive into Distributed Information Processing. We thanks for taking the time to learn this text. See you in our subsequent article!